solution · incident coordination
Coordinated response across your engineering organisation.
Understand operational impact, align ownership, and coordinate escalation to reduce response chaos during incidents.
Move from fragmented response to coordinated operational execution.
- SRE leadership
- Platform engineering
- Incident management
- VP Engineering
- Operations leadership
- CTO
02 · the coordination gap
Incidents become chaotic when operational context is fragmented.
During incidents, teams lose time identifying ownership, understanding dependencies, coordinating escalation, and aligning communications across systems. Response slows because the operational picture is scattered, not because the people are slow.
Operational response stalls when context is buried across disconnected tooling and tribal knowledge. The first ten minutes get spent reconstructing the situation instead of responding to it.
-
Escalation delays
Routing the right responders takes pages, threads, and guesswork. Minutes pass before the team that actually owns the failing component knows it is failing.
-
Dependency confusion
Teams open parallel investigations because nobody can see the affected systems, downstream impact, and shared dependencies in one operational view.
-
Ownership ambiguity
The first ten minutes become a search for who owns what. Responsibility is assumed from last quarter, not recorded against the system that just failed.
-
Communication fragmentation
Updates scatter across chat threads, status pages, and stakeholder DMs. Engineering, leadership, and customer comms drift out of sync within an hour.
03 · incident coordination
Coordinate response with operational context.
Replace parallel investigations and chat archaeology with a continuous operational view of the incident. Coordination stops being something individual responders carry, and becomes something the organisation actually shares.
-
Understand impacted systems
Responders see affected services, dependencies, and downstream products together, not service by service. Scope becomes a shared operational fact, not a debate.
-
Route incidents to the right teams
Routing follows current operational ownership, not stale on-call rosters. The team that gets paged is the team that actually runs the failing component.
-
Coordinate escalation clearly
Escalation paths are operational, not folkloric. When a problem needs to move up, the next responders, owners, and leaders are already known.
-
Reduce operational confusion
Responders converge on one shared picture of the incident instead of reconstructing it from chat scrollback. The same facts reach every team at once.
-
Align stakeholders faster
Engineering, operations, leadership, and customer-facing teams work from one coordinated view of impact, ownership, and response activity.
-
Improve response coordination
Coordination stops being a meeting that happens during the incident and becomes the operational default the moment the incident opens.
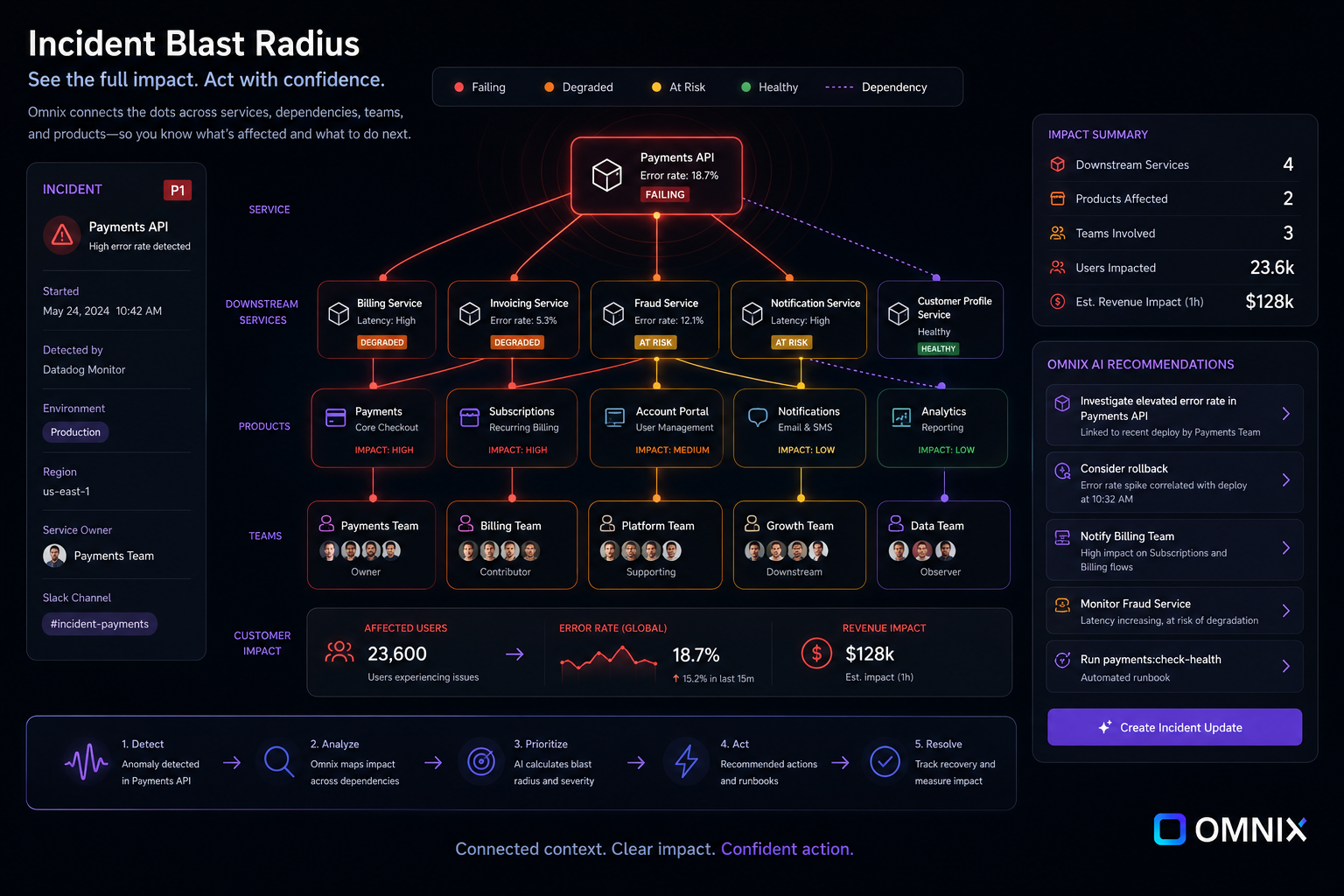
04 · blast radius & impact
Understand operational impact immediately.
Operational response improves when teams can quickly understand dependencies, affected services, downstream impact, and organisational risk. Impact becomes operationally legible from the moment the incident opens.
Severity follows blast radius, not alert volume. Leaders prioritise from organisational risk, and responders converge on the systems that actually need attention first.
-
Dependency visibility
See upstream and downstream relationships immediately. Responders stop discovering hidden dependencies during the incident itself.
-
Impact awareness
Move from 'this service is degraded' to 'this is what is impacted, who owns it, and who needs to coordinate'. Impact becomes operationally legible.
-
Operational prioritisation
Severity follows actual blast radius, not the loudest dashboard. Leaders prioritise from organisational risk, not alert volume.
-
Escalation context
Affected systems, responsible teams, and dependent products are connected to the incident, so escalation conversations start with shared facts.
05 · communication & alignment
Keep teams aligned during operational response.
Incidents create communication fragmentation across engineering, operations, leadership, and customer-facing teams. Updates drift out of sync within an hour when there is no shared operational view.
Omnix helps organisations coordinate updates, ownership, escalation, and response activity across the operational organisation, so internal and external comms stay grounded in the same operational facts.
-
Stakeholder alignment
Engineering, operations, leadership, and customer-facing teams share the same picture of impact, ownership, and response progress.
-
Communication clarity
Updates, owners, and decisions live in one operational view, so internal comms and external comms stop drifting out of sync.
-
Operational coordination
Response activity is coordinated across the responding teams rather than running as parallel investigations on different facts.
-
Response synchronisation
Handoffs carry state. Comms, on-call rotations, and incident leads inherit the operational picture instead of reconstructing it.
06 · response velocity
Reduce coordination delays during incidents.
Operational delays often happen before remediation even starts. The minutes lost to figuring out who responds, who owns what, and which systems are connected become minutes spent actually responding.
When ownership, dependencies, and escalation paths are already attached to the incident, responders stop coordinating about coordinating and start moving.
-
Faster ownership discovery
The minutes lost to figuring out who responds become minutes spent actually responding. Ownership is already attached when the incident opens.
-
Faster escalation routing
Escalation paths are visible and current. Moving a problem up the chain stops being a thread of guesses and becomes a coordinated operational step.
-
Reduced coordination overhead
Responders spend less of the incident on coordination work and more of it on remediation. The coordination layer is already in place.
-
Faster resolution alignment
Once the technical fix lands, leadership, comms, and dependent teams reach the same conclusion at the same time.
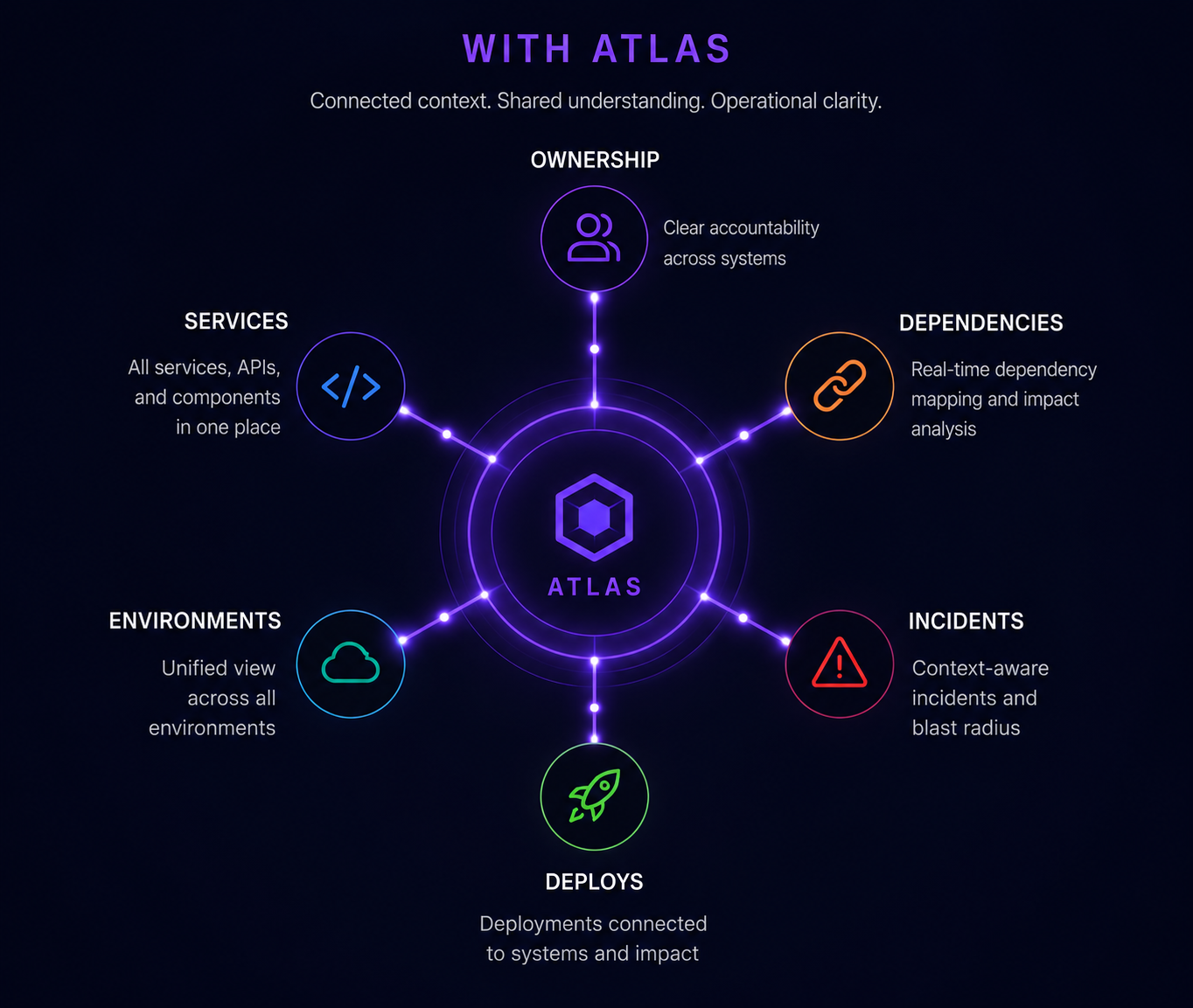
07 · operational resilience
Build calmer operational response systems.
Organisations respond more effectively when operational context, ownership, dependencies, and escalation paths are visible during incidents. Response becomes a coordinated operational practice, not a heroic effort.
Reorgs, on-call changes, and coverage gaps stop being discovered during the incident. Leadership inherits a continuous picture of operational readiness, not a quarterly spreadsheet.
- · Operational maturity
- · Coordination clarity
- · Calmer response
- · Stakeholder confidence
- · Organisational alignment
- · Operational preparedness
08 · operational AI
AI that understands operational incidents.
Omnix AI reasons across systems, ownership, deployments, dependencies, reliability, and operational relationships to surface actionable coordination context during incidents.
-
Contextual reasoning
Reasons across systems, ownership, deployments, dependencies, and reliability signals together when an incident opens, not as separate lookups.
-
Coordination support
Surfaces who is responding, what is impacted, and what has changed recently, so responders coordinate from operational facts instead of recall.
-
Dependency-aware understanding
Understands upstream, downstream, and shared systems together, so impact and escalation context are part of every operational answer.
09 · outcomes
Operational coordination at organisational scale.
What changes when ownership, dependencies, escalation, and communication are shared operational understanding instead of scattered context.
-
Faster incident coordination
-
Reduced escalation delays
-
Improved operational alignment
-
Better dependency visibility
-
Reduced operational confusion
-
Faster stakeholder communication
-
Stronger operational resilience
-
Confident leadership oversight
10 · beyond incident tooling
Beyond incident tooling.
Traditional incident tooling
- · Alert streams
- · Isolated incidents
- · Manual coordination
- · Fragmented communication
- · Limited operational context
- · Escalation by guesswork
Omnix Incident Coordination
- → Coordinated operational response
- → Ownership-aware escalation
- → Dependency-aware impact visibility
- → Organisational alignment
- → Operational context, already attached
- → Cross-team coordination
Most tools give engineering organisations an alert stream.
Omnix gives engineering organisations a coordination layer for response.
see it in action
See coordinated incident response across your engineering organisation.
Book a 30-minute walkthrough. We'll show you what response looks like when impact, ownership, escalation, and communication share one operational view, framed for the way SRE, platform, and engineering leadership actually coordinate.
- Read-only access. We never push, comment, or merge.
- SOC 2 Type II in progress. Audit period H2 2026.
- Code stays in your VCS. We read metadata, not your repo contents.