solution · reliability management
Operational reliability across your engineering organisation.
Understand reliability risk, operational health, dependencies, ownership, and resilience across systems, teams, and services.
Move from fragmented monitoring to coordinated operational reliability.
- SRE leadership
- Platform engineering
- Reliability engineering
- VP Engineering
- Operations leadership
- CTO
02 · the reliability gap
Reliability becomes harder as systems and teams scale.
Operational reliability signals fragment across observability, infrastructure, deployment, and incident tooling. Teams lose visibility into operational risk, dependency impact, ownership, and resilience coordination the moment those signals stop sharing context.
Reliability stops being something the organisation manages and starts being something individual teams cope with. Coordination overhead grows faster than the platform does, and operational risk hides in the gaps between tools.
-
Operational blind spots
Reliability signals scatter across observability, infrastructure, deployment, and incident tooling. Nobody owns the picture, so nobody really has it.
-
Dependency uncertainty
Teams know their own services. They do not know which products a degraded dependency quietly affects, or which other teams should already be looking.
-
Reactive firefighting
Reliability work happens after the page, not before. Operational risk is rediscovered every quarter through an outage instead of surfaced before it escalates.
-
Coordination overhead
Cross-team reliability conversations stall on different dashboards, different definitions, and different snapshots of who owns what right now.
03 · reliability visibility
Understand operational health across the organisation.
Replace per-team dashboards and scattered reliability snapshots with a continuous operational view of services, dependencies, ownership, and risk. Reliability stops being something each team interprets alone, and becomes something the organisation actually shares.
-
Service reliability understanding
See operational health across services, products, and dependencies in one connected view, so reliability becomes an organisational fact, not a per-team interpretation.
-
Dependency-aware health
Health is read in context. A degrading service is shown alongside the products it powers, the teams that own it, and the systems it depends on.
-
Cross-organisational awareness
Leadership, platform, and product engineering work from one continuous reliability picture instead of reconciling weekly snapshots from different tools.
-
Reliability prioritisation
Operational attention follows organisational risk and product impact, not alert volume or whichever dashboard happens to be open.
-
Resilience coordination
Reliability work coordinates across teams the same way the systems do, with shared context for ownership, dependencies, and operational state.
-
Operational health awareness
Degradation, drift, and risk are visible early, so reliability conversations move from reacting to incidents to managing operational health continuously.
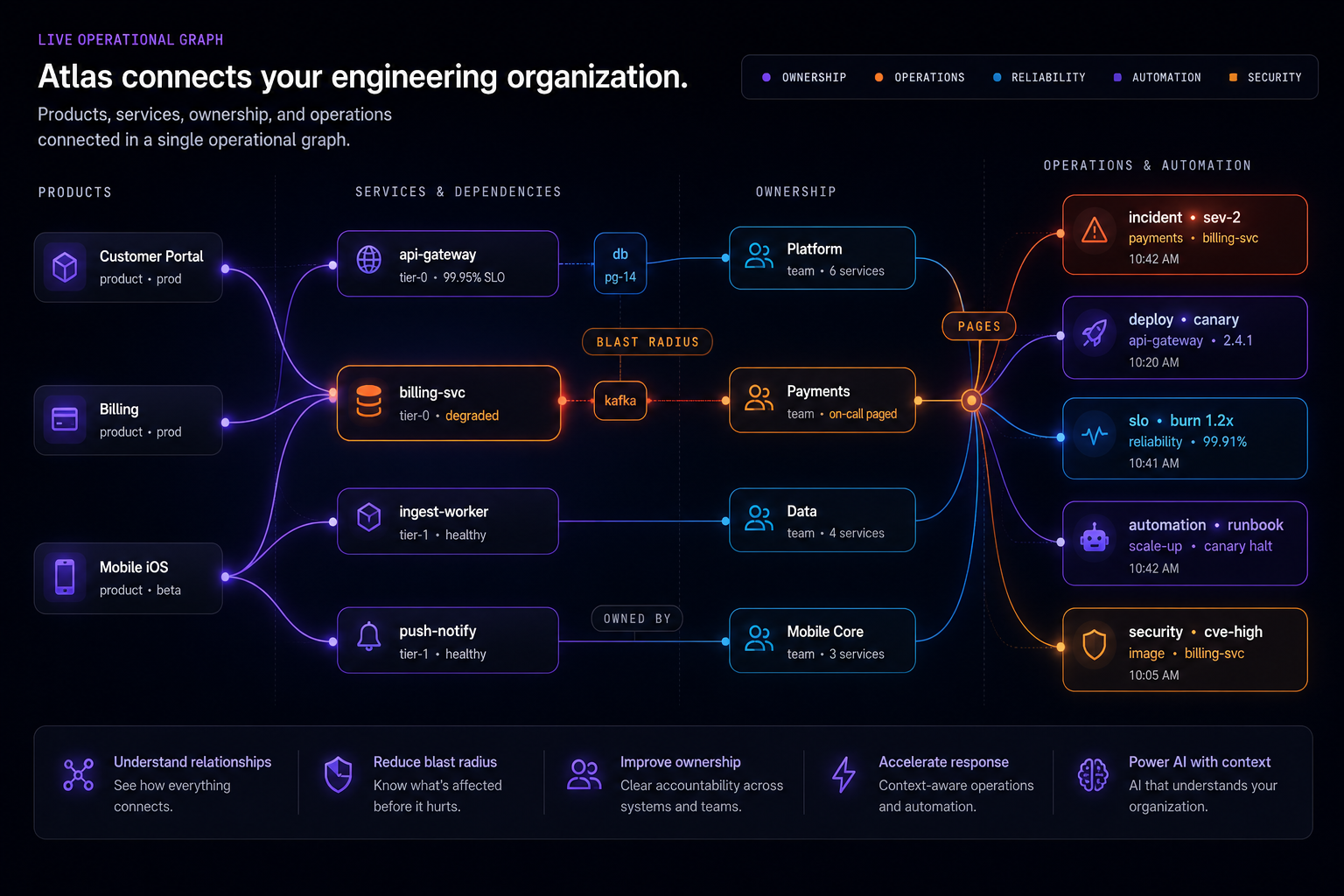
04 · dependency & impact
Understand what reliability issues affect.
Operational reliability improves when teams understand dependencies, downstream impact, ownership, and organisational risk together. A degraded service stops being a row in a list and becomes a position in a connected operational picture.
Reliability conversations move from describing systems to reasoning about impact. Severity follows actual blast radius, not the loudest dashboard, and leadership prioritises from organisational risk instead of alert volume.
-
Blast radius visibility
See what a reliability issue actually affects: downstream services, dependent products, and the teams who already need to know.
-
Dependency relationships
Upstream and downstream connections are explicit. Reliability conversations stop being a tour of internal mental models.
-
Operational impact
Move from 'this service is degraded' to 'this is what is impacted, who owns it, and how it propagates'. Impact becomes operationally legible.
-
Downstream risk
A weakening dependency is visible to the products that rely on it, so risk does not stay buried inside the team that runs the service.
05 · reliability ownership
Connect reliability to ownership and accountability.
Reliability coordination improves when ownership, escalation responsibility, and operational accountability are visible across systems and teams. Ownership stops drifting between reorgs and lives where the systems live.
Operational accountability becomes an organisational capability instead of a heroic individual one. Coverage is something leadership can actually see, not something the company hopes is in place.
-
Operational accountability
Every service, dependency, and reliability surface has an owner attached. Accountability stops drifting between reorgs and lives where the systems live.
-
Reliability ownership
Service owners, escalation contacts, and operational responsibilities are connected to reliability state, not stored in a separate spreadsheet.
-
Escalation clarity
When operational health degrades, the responsible team, escalation path, and adjacent owners are already known, not searched for.
-
Resilience management
Reliability ownership becomes an organisational capability instead of a heroic individual one. Ownership coverage is something leadership can actually see.
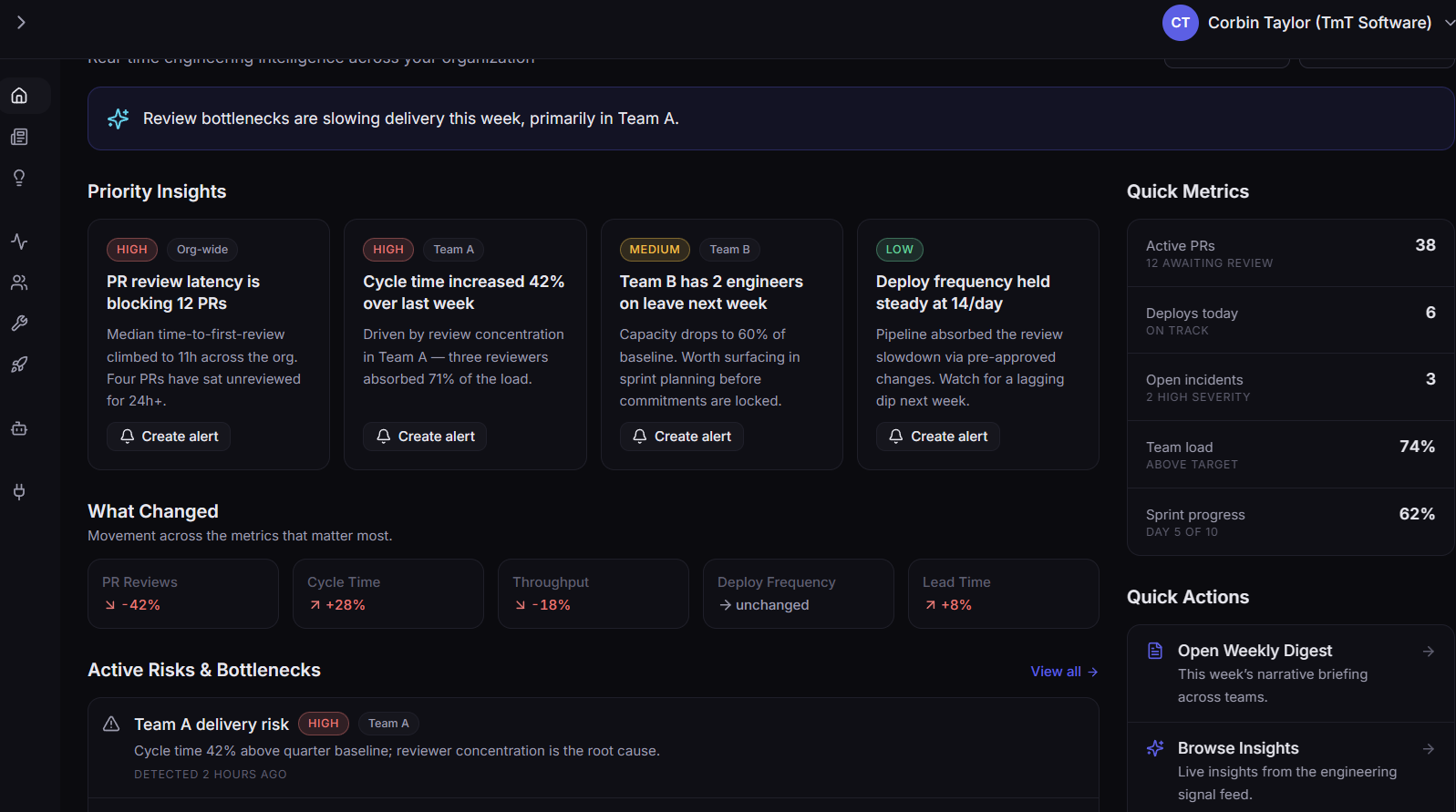
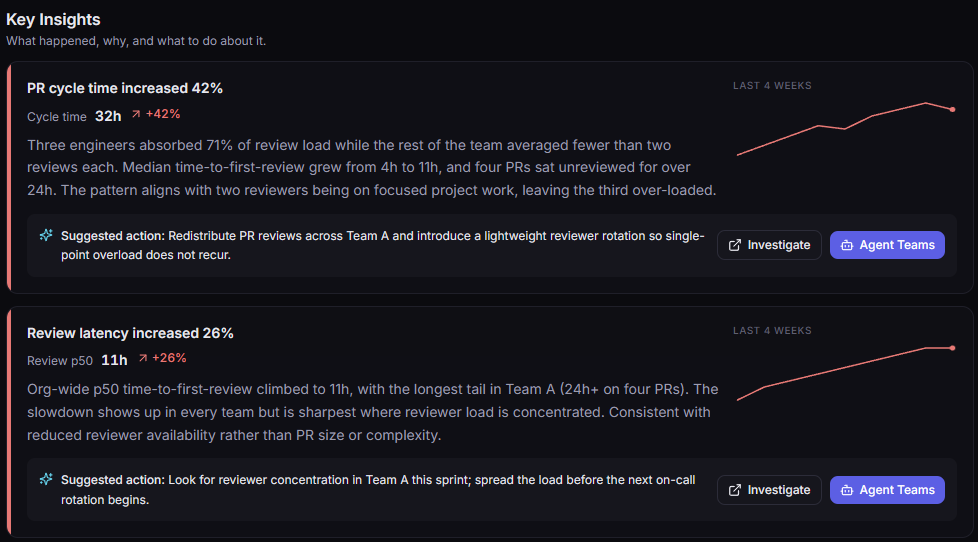
06 · proactive risk
Surface operational risk before systems fail.
Organisations become more resilient when operational degradation, deployment impact, reliability drift, and dependency risk are visible before incidents escalate. Reliability becomes a managed posture, not a recovery effort.
Risk surfaces in the same operational view as ownership and dependencies, so prioritising it is a leadership decision, not a fire-drill. Reliability investment follows current operational state, not last quarter's incident review.
-
Operational risk awareness
Reliability drift, dependency weakening, and ownership gaps surface as operational risk before they show up as incidents.
-
Deployment risk visibility
Recent changes are connected to the services and dependencies they touch, so reliability impact is visible during release, not during rollback.
-
Reliability drift
Slow-moving degradation, missing runbooks, and unowned tier-0 surfaces are surfaced as standing operational risk, not as quarterly audit findings.
-
Operational foresight
Leadership inherits a continuous picture of operational risk, so reliability investment is informed by current state, not last quarter's incident review.
07 · engineering resilience
Build resilient engineering systems.
Operational resilience depends on more than monitoring. It requires organisational coordination, dependency awareness, ownership visibility, and operational understanding working together as a single operational picture.
Reorgs, on-call changes, and coverage gaps stop being discovered during the next outage. Leadership inherits a continuous picture of operational readiness, not a quarterly spreadsheet.
- · Resilience maturity
- · Organisational coordination
- · Operational preparedness
- · Engineering alignment
- · Systemic reliability
- · Cross-team awareness
08 · operational AI
AI that understands operational reliability.
Omnix AI reasons across deployments, dependencies, ownership, incidents, operational health, and organisational context to surface meaningful reliability understanding, not isolated metrics.
-
Contextual reliability
Reasons across services, ownership, dependencies, deployments, and operational health together, so reliability questions are answered with organisational context attached.
-
Operational awareness
Surfaces what changed, what is at risk, and which teams already share the picture, so reliability understanding is a shared operational fact.
-
Dependency reasoning
Understands upstream, downstream, and cross-team relationships, so reliability impact is reasoned about across the organisation, not service by service.
09 · outcomes
Operational resilience at organisational scale.
What changes when reliability, ownership, dependencies, and operational risk are shared operational understanding instead of fragmented context.
-
Improved operational visibility
-
Faster reliability coordination
-
Reduced operational blind spots
-
Better dependency awareness
-
Stronger resilience planning
-
Improved reliability ownership
-
Reduced reactive firefighting
-
Better operational prioritisation
10 · beyond monitoring & observability
Beyond monitoring and observability.
Traditional reliability tooling
- · Isolated telemetry
- · Monitoring dashboards
- · Fragmented reliability visibility
- · Reactive alerting
- · Manual operational coordination
- · Per-team reliability views
Omnix Reliability Management
- → Organisational reliability understanding
- → Dependency-aware visibility
- → Ownership-aware coordination
- → Proactive operational resilience
- → Context-aware reliability intelligence
- → Cross-system operational understanding
Most tools give engineering organisations a stream of metrics.
Omnix gives engineering organisations an operational reliability layer.
see it in action
See operational reliability across your engineering organisation.
Book a 30-minute walkthrough. We'll show you what reliability looks like when service health, dependencies, ownership, and operational risk share one connected view, framed for the way SRE, platform, and engineering leadership actually coordinate.
- Read-only access. We never push, comment, or merge.
- SOC 2 Type II in progress. Audit period H2 2026.
- Code stays in your VCS. We read metadata, not your repo contents.